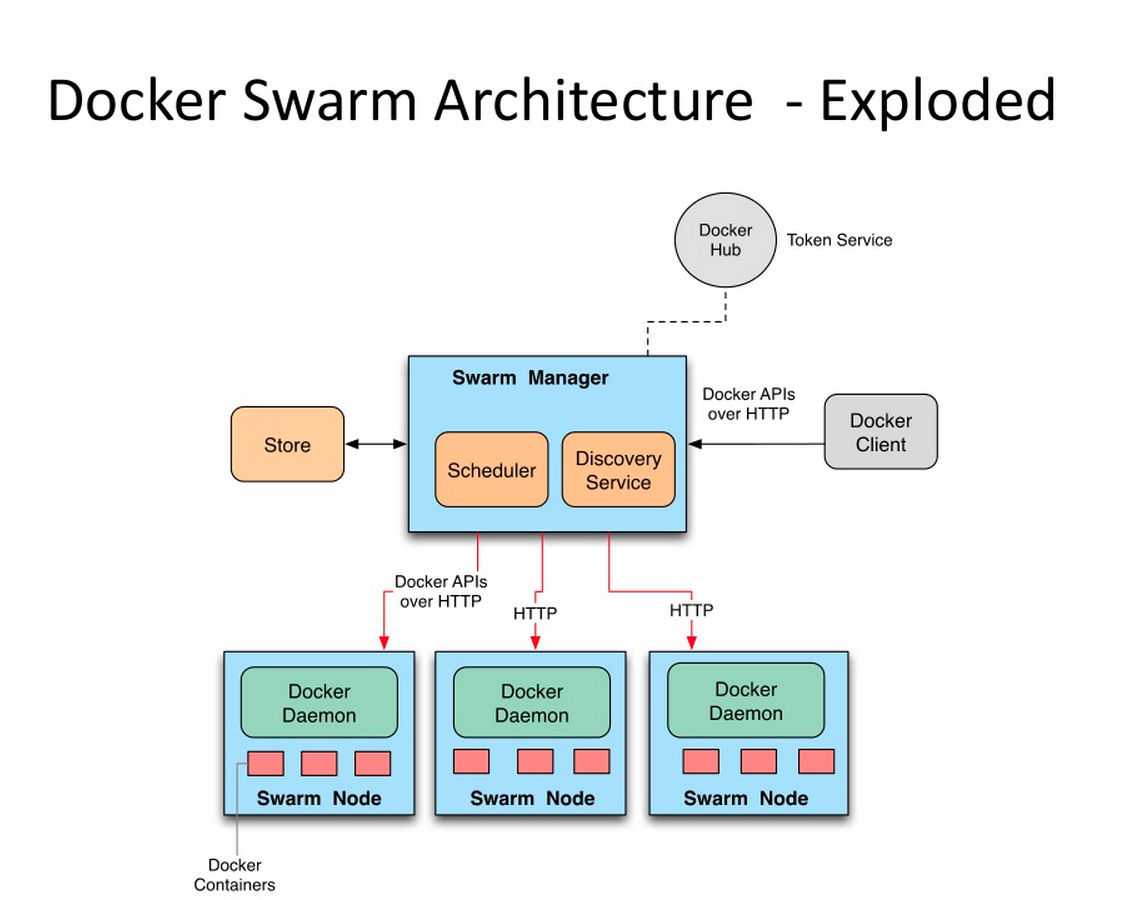
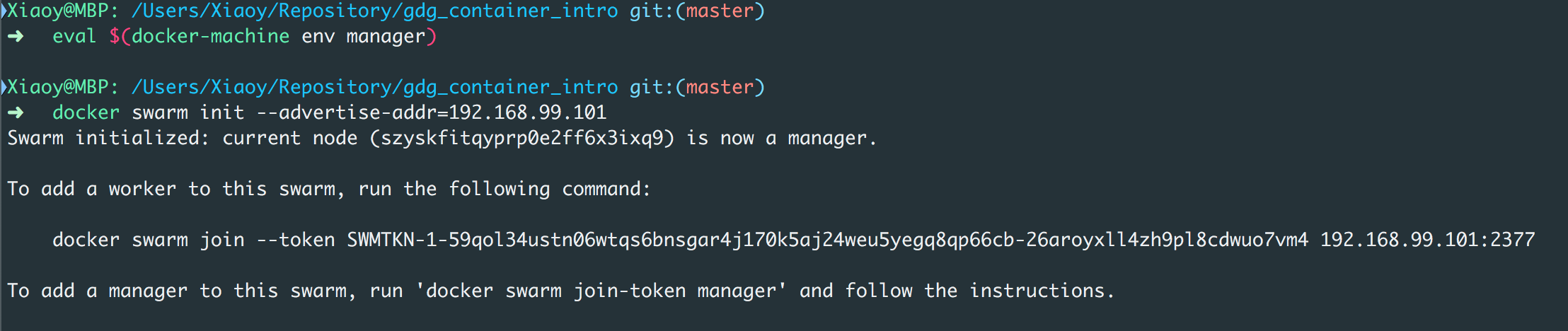
Keep Codingfrom a coder2020-07-22T08:25:04.000Zhttps://yuechuanx.top/Yuechuan XiaoHexo<流畅的Python>:可迭代的对象、迭代器和生成器https://yuechuanx.top/Python/fluent-python-notes-chap-14/2020-07-22T08:25:04.000Z2020-07-22T08:25:04.000Z
def__next__(self): """调用时返回下一个对象""" try: word = self.words[self._index] except IndexError: raise StopIteration() else: self._index += 1 return word
sentence = Sentence('Return a list of all non-overlapping matches in the string.') assert isinstance(sentence, abc.Iterable) # 实现了 __iter__,就支持 Iterable 协议 assert isinstance(iter(sentence), abc.Iterator) for word in sentence: print(word, end='·')
首先进行深度遍历,结果为 [C, A, X, object, Y, object, B, Y, object, X, object];然后,只保留重复元素的最后一个,结果为 [C, A, B, Y, X, object]。Python 2.2 在实现该方法的时候进行了调整,使其更尊重基类中类出现的顺序,其实际结果为 [C, A, B, X, Y, object]。
这样的结果是否合理呢?首先我们看下各个类中的方法解析顺序:对于 A 来说,其搜索顺序为 [A, X, Y, object];对于 B,其搜索顺序为 [B, Y, X, object];对于 C,其搜索顺序为 [C, A, B, X, Y, object]。我们会发现,B 和 C 中 X、Y 的搜索顺序是相反的!也就是说,当 B 被继承时,它本身的行为竟然也发生了改变,这很容易导致不易察觉的错误。此外,即使把 C 搜索顺序中 X 和 Y 互换仍然不能解决问题,这时候它又会和 A 中的搜索顺序相矛盾。
A MRO is monotonic when the following is true: if C1 precedes C2 in the linearization of C, then C1 precedes C2 in the linearization of any subclass of C. Otherwise, the innocuous operation of deriving a new class could change the resolution order of methods, potentially introducing very subtle bugs.
>>> classC(A, B):pass Traceback (most recent call last): File "<ipython-input-8-01bae83dc806>", line 1, in <module> classC(A, B):pass TypeError: Error when calling the metaclass bases Cannot create a consistent method resolution order (MRO) for bases X, Y
我们把类 C 的线性化(MRO)记为 L[C] = [C1, C2,…,CN]。其中 C1 称为 L[C] 的头,其余元素 [C2,…,CN] 称为尾。如果一个类 C 继承自基类 B1、B2、……、BN,那么我们可以根据以下两步计算出 L[C]:
L[object] = [object]
L[C(B1…BN)] = [C] + merge(L[B1]…L[BN], [B1]…[BN])
这里的关键在于 merge,其输入是一组列表,按照如下方式输出一个列表:
检查第一个列表的头元素(如 L[B1] 的头),记作 H。
若 H 未出现在其它列表的尾部,则将其输出,并将其从所有列表中删除,然后回到步骤1;否则,取出下一个列表的头部记作 H,继续该步骤。
digraph MyGraph { a [shape=box] b [shape=polygon,sides=6] c [shape=triangle] d [shape=invtriangle] e [shape=polygon,sides=4,skew=.5] f [shape=polygon,sides=4,distortion=.5] g [shape=diamond] h [shape=Mdiamond] i [shape=Msquare] a -> b a -> c a -> d a -> e a -> f a -> g a -> h a -> i }
digraph MyGraph { a [style=filled,color=green] b [peripheries=4,color=blue] c [fontcolor=crimson] d [style=filled,fillcolor=dodgerblue,color=coral4,penwidth=3] e [style=dotted] f [style=dashed] g [style=diagonals] h [style=filled,color="#333399"] i [style=filled,color="#ff000055"] j [shape=box,style=striped,fillcolor="red:green:blue"] k [style=wedged,fillcolor="green:white:red"] a -> b a -> c a -> d a -> e b -> f b -> g b -> h b -> i d -> j j -> k }
digraph MyGraph { a -> b [dir=both,arrowhead=open,arrowtail=inv] a -> c [dir=both,arrowhead=dot,arrowtail=invdot] a -> d [dir=both,arrowhead=odot,arrowtail=invodot] a -> e [dir=both,arrowhead=tee,arrowtail=empty] a -> f [dir=both,arrowhead=halfopen,arrowtail=crow] a -> g [dir=both,arrowhead=diamond,arrowtail=box] }
digraph MyGraph { a -> b [color="black:red:blue"] a -> c [color="black:red;0.5:blue"] a -> d [dir=none,color="green:red:blue"] a -> e [dir=none,color="green:red;.3:blue"] a -> f [dir=none,color="orange"] d -> g [arrowsize=2.5] d -> h [style=dashed] d -> i [style=dotted] d -> j [penwidth=5] }
digraph MyGraph { begin [label="This is the beginning"] end [label="It ends here"] begin -> end }
以及顶点:
1 2 3 4 5
digraph MyGraph { begin end begin -> end [label="Beginning to end"] }
我们可以设置标签样式:
1 2 3 4 5
digraph MyGraph { begin [label="This is the beginning",fontcolor=green,fontsize=10] end [label="It ends here",fontcolor=red,fontsize=10] begin -> end [label="Beginning to end",fontcolor=gray,fontsize=16] }
集群
聚类也称为子图。集群的名称必须以开头cluster_,否则将不会包含在框中。
1 2 3 4 5 6 7 8
digraph MyGraph { subgraph cluster_a { b c -> d } a -> b d -> e }
集群可以根据需要嵌套:
1 2 3 4 5 6 7 8 9 10 11 12 13
digraph MyGraph { subgraph cluster_a { subgraph cluster_b { subgraph cluster_c { d } c -> d } b -> c } a -> b d -> e }
#!/usr/bin/python #**coding:utf-8** import sys from prettytable import PrettyTable from prettytable import MSWORD_FRIENDLY from prettytable import PLAIN_COLUMNS from prettytable import RANDOM from prettytable import DEFAULT
list(map(fact, range(6))) [fact(n) for n in range(6)] list(map(factorial, filter(lambda n : n % 2, range(6)))) [factorial(n) for n in range(6) if n % 2]
map 和 filter 返回生成器,可用生成器表达式替代 reduce 常用求和,目前最好使用 sum 替代
1 2 3 4 5
from functools import reduce from operator import add
]]>
<blockquote>
<p>不管别人怎么说或怎么想,我从未觉得 Python 受到来自函数式语言的太多影响。我非常熟悉命令式语言,如 C 和 Algol 68,虽然我把函数定为一等对象,但是我并不把 Python 当作函数式编程语言。<br />
—— Guido van R
Zen of Python(Python之禅)https://yuechuanx.top/Python/zen-of-python/2020-04-15T08:54:29.000Z2020-04-15T08:54:29.000ZBeautiful is better than ugly. (优美比丑陋好)
Explicit is better than implicit.(清晰比晦涩好)
Simple is better than complex.(简单比复杂好)
Complex is better than complicated.(复杂比错综复杂好)
Flat is better than nested.(扁平比嵌套好)
Sparse is better than dense.(稀疏比密集好)
Readability counts.(可读性很重要)
Special cases aren’t special enough to break the rules.(特殊情况也不应该违反这些规则)
Although practicality beats purity.(但现实往往并不那么完美)
Errors should never pass silently.(异常不应该被静默处理)
Unless explicitly silenced.(除非你希望如此)
In the face of ambiguity, refuse the temptation to guess.(遇到模棱两可的地方,不要胡乱猜测)
There should be one-- and preferably only one --obvious way to do it.(肯定有一种通常也是唯一一种最佳的解决方案)
Although that way may not be obvious at first unless you’re Dutch.(虽然这种方案并不是显而易见的,因为你不是那个荷兰人这里指的是Python之父Guido)
Now is better than never.(现在开始做比不做好)
Although never is often better than *right* now.(不做比盲目去做好极限编程中的YAGNI原则)
If the implementation is hard to explain, it’s a bad idea.(如果一个实现方案难于理解,它就不是一个好的方案)
If the implementation is easy to explain, it may be a good idea.(如果一个实现方案易于理解,它很有可能是一个好的方案)
Namespaces are one honking great idea – let’s do more of those!(命名空间非常有用,我们应当多加利用)
]]>
<p>Beautiful is better than ugly. (优美比丑陋好)</p>
<p>Explicit is better than implicit.(清晰比晦涩好)</p>
<p>Simple is better than complex.(简单比复杂好)</p
Django 导出和导入数据https://yuechuanx.top/django-dumpdata-and-loaddata/2020-04-13T10:57:03.000Z2020-04-13T10:57:03.000Zdumpdata 命令:
Output the contents of the database as a fixture of the given format (using each model's default manager unless --all is specified). positional arguments: app_label[.ModelName] Restricts dumped data to the specified app_label or app_label.ModelName. optional arguments: -h, --help show this help message and exit --format FORMAT Specifies the output serialization format for fixtures. --indent INDENT Specifies the indent level to use when pretty-printing output. --database DATABASE Nominates a specific database to dump fixtures from. Defaults to the "default" database. -e EXCLUDE, --exclude EXCLUDE An app_label or app_label.ModelName to exclude (use multiple --exclude to exclude multiple apps/models). --natural-foreign Use natural foreign keys if they are available. --natural-primary Use natural primary keys if they are available. -a, --all Use Django's base manager to dump all models stored in the database, including those that would otherwise be filtered or modified by a custom manager. --pks PRIMARY_KEYS Only dump objects with given primary keys. Accepts a comma-separated list of keys. This option only works when you specify one model. -o OUTPUT, --output OUTPUT Specifies file to which the output is written. --version show program's version number and exit -v {0,1,2,3}, --verbosity {0,1,2,3} Verbosity level; 0=minimal output, 1=normal output, 2=verbose output, 3=very verbose output --settings SETTINGS The Python path to a settings module, e.g. "myproject.settings.main". If this isn't provided, the DJANGO_SETTINGS_MODULE environment variable will be used. --pythonpath PYTHONPATH A directory to add to the Python path, e.g. "/home/djangoprojects/myproject". --traceback Raise on CommandError exceptions --no-color Don't colorize the command output. --force-color Force colorization of the command output.
""" Docstring reporter.py is used to generate a html report for specific build. """
# Standard library import os import re from collections import namedtuple
# Third party lib # Import multi-subcass from A package. from jinja2 import ( Environment, FileSystemLoader, Template, select_autoescape) from jira import JIRA
# If you have lcoal import # from .utils import X # from . import utils
要优于 try: # Too broad! return handle_value(collection[key]) except KeyError: # Will also catch KeyError raised by handle_value() return key_not_found(key)
使用startswith() and endswith()代替切片进行序列前缀或后缀的检查。比如
1 2 3 4 5
Yes: if foo.startswith(‘bar’):优于 No: if foo[:3] == ‘bar’: - 使用isinstance()比较对象的类型。比如 Yes: if isinstance(obj, int): 优于 No: if type(obj) is type(1):
判断序列空或不空,有如下规则
1 2 3 4 5
Yes: ifnot seq: if seq: 优于 No: if len(seq) ifnot len(seq)
# 字典提供了很多种构造方法 a = dict(one=1, two=2, three=3) b = {'one': 1, 'two': 2, 'three': 3} c = dict(zip(['one', 'two', 'three'], [1, 2, 3])) d = dict([('two', 2), ('one', 1), ('three', 3)]) e = dict({'three': 3, 'one': 1, 'two': 2}) a == b == c == d == e
index = {} with open(sys.argv[1], encoding='uft-8') as fp: for line_no, line in enumerate(fp, 1): for match in WORD_RE.finditer(line): word = match.group() column_no = match.start() + 1 location = (line_no, column_no) # 提取单词出现情况,如果没有出现过返回 [] occurences = index.get(word, []) occurences.append(location) index[word] = occurences
# 以字符顺序打印结果 for word in sorted(index, key=str.upper): print(word, index[word])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
$ python index0.py zen.txt a [(19, 48), (20, 53)] Although [(11, 1), (16, 1), (18, 1)] ambiguity [(14, 16)] and [(15, 23)] are [(21, 12)] aren [(10, 15)] at [(16, 38)] bad [(19, 50)] be [(15, 14), (16, 27), (20, 50)] beats [(11, 23)] Beautiful [(3, 1)] better [(3, 14), (4, 13), (5, 11), (6, 12), (7, 9), (8, 11), (17, 8), (18, 25)] break [(10, 40)] by [(1, 20)] cases [(10, 9)] complex [(5, 23)] ...
index = {} with open(sys.argv[1], encoding='uft-8') as fp: for line_no, line in enumerate(fp, 1): for match in WORD_RE.finditer(line): word = match.group() column_no = match.start() + 1 location = (line_no, column_no) # 注意这行与上面的区别 index.setdefault(word, []).append(location) # 效果等同于: # if key not in my_dict: # my_dict[key] = [] # my_dict[key].append(new_value)
# 以字符顺序打印结果 for word in sorted(index, key=str.upper): print(word, index[word])
index = collections.defaultdict(list) with open(sys.argv[1], encoding='utf-8') as fp: for line_no, line in enumerate(fp, 1): for match in WORD_RE.finditer(line): word = match.group() column_no = match.start()+1 location = (line_no, column_no) # index 如何没有 word 的记录, default_factory 会被调用,这里是创建一个空列表返回 index[word].append(location)
# print in alphabetical order for word in sorted(index, key=str.upper): print(word, index[word])
# 比较两段代码 symbols = 'abcde' # 1 codes = [] for symbol in symbols: codes.append(ord(symbol)) print(codes) # 2 codes = [ord(symbol) for symbol in symbols] print(codes)
列表推导能够提升可读性。 只用列表推导来创建新的列表,并尽量保持简短(不要超过一行)
列表推导同 filter 和 map 的比较
1 2 3 4 5 6 7
symbols = 'abcde'
beyond_ascii = [ord(s) for s in symbols if ord(s) > 100] print(beyond_ascii)
beyond_ascii = list(filter(lambda c: c > 100, map(ord, symbols))) print(beyond_ascii)
# 需要两个参数,类名和类各个字段的名字 City = namedtuple('City', 'name country population coordinates') tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 129.691667)) print(tokyo) print(tokyo.population) print(tokyo.coordinates)
RUN apt-get update RUN apt-get upgrade -y RUN apt-get install -y nodejs ssh mysql RUNcd /app && npm install
# this should start three processes, mysql and ssh # in the background and node app in foreground # isn't it beautifully terrible? <3 CMD mysql & sshd & npm start
#!/usr/bin/env sh # $0 is a script name, # $1, $2, $3 etc are passed arguments # $1 is our command CMD=$1
case"$CMD"in "dev" ) npm install export NODE_ENV=development exec npm run dev ;;
"start" ) # we can modify files here, using ENV variables passed in # "docker create" command. It can't be done during build process. echo"db: $DATABASE_ADDRESS" >> /app/config.yml export NODE_ENV=production exec npm start ;;
* ) # Run custom command. Thanks to this line we can still use # "docker run our_image /bin/bash" and it will work exec$CMD${@:2} ;; esac
# env variables required during build ENV PROJECT_DIR=/app
WORKDIR$PROJECT_DIR
COPY package.json $PROJECT_DIR RUN npm install COPY . $PROJECT_DIR
# env variables that can change # volume and port settings # and defaults for our application ENV MEDIA_DIR=/media \ NODE_ENV=production \ APP_PORT=3000